











This article is taken from the book, Testing Dirty Systems, co-authored with William E. Perry. A dirty system is one that is undocumented, patched over by constant maintenance, and is unstructured. This information is also taken from our training course, Integration and Interoperability Testing.
A type of test case that needs to be present in testing dirty systems is the regression test case. It seems that dirty systems are especially exposed to the regression risk, which is seen when a change to a validated piece of software causes a new defect to occur. Regression defects are a fact of life in software, especially software maintenance, which forces people to test more than just changes.
The key issue in regression testing is knowing how many test cases are needed to test a new release. The answer to this issue depends on:
The relative risk of the system being tested
If the potential impact of defects are minimal, then to test a large number of cases every time a change is made would be overkill. However, if property or safety are at risk, a large number of regression test cases would be very appropriate.
The level of system integration
This is a two-edged sword, in that on one hand highly integrated systems seem to be prone to regression defects due to the complex nature of many interfaces. A change in one module could manifest a defect in another module far downstream in the processing flow. On the other hand, highly integrated systems are difficult to regression test because of the large number of possible test cases required to adequately cover the integration paths. If we could predict where the defects might be, we wouldn't need to perform regression testing. However, that's not the case with most dirty systems.
The scope of the change
This is also a difficult criteria to define exactly. It is tempting to want to reduce the level of regression testing because a change might be very small. However, experience tells us that some major software failures can be traced back to a singe simple change. Consider the following examples:
On January 15, 1990, 114 switching computers in the AT&T telephone network crashed because of a single coding error. A misplaced "break" command in a C language program caused local computers to go down and broadcast "out of service" messages to be broadcast. The condition lasted for over nine hours in which switches failed, rebooted, only to fail again when restarted. The estimated cost of the outage was $60 million dollars and loss of company reputation. (Reference Globe and Mail, November 12, 1990, Page B8)
A spacecraft headed toward Venus, the Atlas-Agena, was blown up after it became unstable at an altitude of 90 miles. The problem was traced back to a missing hyphen in the flight plan. The cost of the spacecraft was $18 million. (Computer-Related Risks by Peter G. Neumann, Pg 26)
Of course, these are very visible examples of notable failures and don't happen to this extent every day, thank goodness. The point we are making my presenting them is that a small defect can have a huge impact. You can find a listing of many other classics software problems at: http://www.softwareqatest.com/qatfaq1.html#FAQ1_3.
Boris Beizer has also been quoted as saying that the top five software problems in his list are all related to unit defects. They are:
1. The Voyager bug (sent the probe into the sun).
2. The AT&T bug that took out 1/3 of US telephones.
3. The DCS bug that took out the other 1/3 a few months later.
4. The Intel Pentium chip bug (it was software, not hardware).
5. The Ariane V bug.
Letter to swtest-discuss, 10 June 1997
In a follow-up letter, Beizer stated that the Therac 25 defect which was responsible for the maiming and deaths of six people by overdosing of radiation therapy was notorious, but not a unit defect. You can find a complete description of that defect in the book, Fatal Defect by Ivars Peterson.
The resources available to perform regression testing
These resources include time, environments, people and tools. There are times when you can see the need to perform a certain level of regression testing, but are constrained by the lack of resources. This is a real-world situation which goes back to management support of testing. People can only do the job they have the resources to perform. Regression testing without automated test tools is so imprecise and laborious it could well be called "pseudo-regression testing."
A Risk-Based Process for Regression Testing of Dirty Systems
The best advice I can give for the regression testing of dirty systems is to base the extent of testing on relative risk. If the risk is high, you will want to develop a repeatable set of test cases that represents the widest scope of testing possible and perform those tests each time a change is made to the software. If the risk is low, you can test with a subset of regression test cases.
The following diagrams illustrate the effect of segmenting regression test cases by risk. In each diagram a universe of test cases is defined. However, we are quick to agree that number of possible test cases approaches infinity for many applications. The universe as shown in the diagrams is a practical "line-of-sight" view of those test cases known to be needed and effective.
In Figure 1, the high risk environment contains all test cases that are known to exist.
Figure 1 - The Universe of Test Cases
In Figure 2, the test cases are segmented by risk. In this environment, there are some parts of the application that can be regression tested at lesser degrees than others.
Figure 2 - Multiple Levels of Risk in the Universe of Test Cases
We must be quick to point out that in dirty systems, and even those are clean, that varying levels of risk can be seen spread across a function. When this occurs, the multiple test cases that may be required to test such a function will also have varying levels of risk. We mention this because sometimes in testing the high risk functions you must also test the low risk functions.
In Figure 3 the effect of varying levels of risk in a transaction or major function are shown by the linking together of test cases that are required to test the major function.
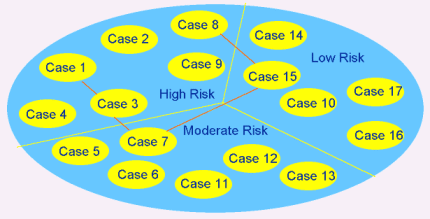
Figure 3 - Varying Levels of Risk in a Major Function or Transaction
This is perhaps the most difficult of the regression test situations because the risk cuts across all levels. In such a situation, the regression test would be required to include all of the test cases, regardless of the lower levels of risk seen in some of the cases.
Common Regression Test Approaches
The following regression test approaches are not necessarily right or wrong for you. The approach depends on your risk and the application you are testing. This is simply a list of some of the more common ways regression testing is applied.
-
Test Everything, Every Time
Rationale: The risk of failure in a particular application is so high that it outweighs the cost of massive test efforts.
Benefits: A high level of test coverage is achieved.
Risks: If done manually, the chances are low that every case is actually being tested, since there is a high likelihood of human error. In addition, the burden of performing such an intense test manually can lead to tester burnout.
-
Test a Few Things Every Time a Change is Made
Rationale: The risk of failure is too low or the deadlines are too close to justify testing a large number of cases.
Benefits: If the risk is actually low, the level of testing matches the level of risk.
Risks: If the risk is higher than estimated, the level of regression testing may be too low.
-
Test Even When a Change is Not Made
Rationale: The risk of failure is high and there are external factors that are not under the control of software configuration management that could impact systematic behavior.
Benefits: The application is undergoing continuous monitoring.
Risks: Unless automated, this level of testing can be overwhelming. Sometimes a false sense of security can be realized since the regression test is only as complete as the defined test cases.
-
Test Critical Cases Every Time a Change is Made
Rationale: The risk of failure is low to moderate and there is a way to assess relative risk. Testing is optimized to increase value and decrease redundancy. This method is seen many times when test automation is not used, or when the possible number of regression test cases is large, even for the use of automated test tools.
Benefits: Testing matches risk. For manual testing, there is a way to balance the need for regression testing with the realization that there will always be a risk of missing the definition or performance of a test case.
Risks: A test case that is necessary may not be included in the regression set.
-
Test Critical Cases Even When a Change is Not Made
Rationale: The risk of failure is low to moderate and there are external factors that are not under the control of software configuration management that could impact systematic behavior.
Benefits: The application is undergoing continuous monitoring.
Risks: Unless automated, this level of testing can be overwhelming. Sometimes a false sense of security can be realized since the regression test is only as complete as the defined test cases. A test case that is necessary may not be included in the regression set.
Regression Testing Approach Checklist
|
# |
Criteria |
Yes |
No |
|
1 |
Should your application fail, would the negative impact be high? |
|
|
|
2 |
Are changes being made to any part of the system on a frequent basis? |
|
|
|
3 |
Are changes being made to any part of the system outside of the control of your organization? |
|
|
|
4 |
Is it possible for you to define a set of regression test cases that completely defines all functionality? |
|
|
|
5 |
Is it possible for you to define a set of regression test cases that completely defines critical functionality? |
|
|
The above checklist is subjective in points such as "high impact" and "on a frequent basis." This subjectivity is intentional, since impact and frequency are relative to each application environment. Therefore, you need what constitutes "high impact" and "frequent basis" for your organization and applications.
The purpose of the checklist is to lead you through the questions that will help you determine the level of regression testing that is most appropriate for you. For example, if you answer questions 1, 3 and 4 with a "yes" , then you could be a candidate for testing every condition on a regular interval.
The Regression Testing Process
In the above process, the following steps are performed:
Step 1 - Test existing software using test data containing pre-modified test cases. The results of this test will be the baseline to compare against.
Step 2 - The software/system is modified.
Step 3 - Modify the test data to contain new test cases to validate changes.
Step 4 - Test modified software using modified test data.
Step 5 - Compare the post-modified test results with the pre-modified test results. Any differences should be identified as potential defects.
Continually Building the Regression Set
As the application continues to undergo maintenance, new regression test cases will need to be added. These cases will be derived from cases required to test new functionality, and from test cases created from the identification and repair of defects.
Tips for Performing Regression Testing
-
Control the scope of testing.
You only have so much time for testing, so choose your tests carefully.
-
Build a reusable test bed of data.
A reusable test bed of data is essential for regression testing.
-
Use automated tools.
Especially when it comes to on-line regression testing, automated capture/playback tools are the only way to achieve exact regression testing.
-
Base the amount of regression testing on risk.
By its very nature, regression testing is redundant. You can manage the redundancy by basing your testing on risk.
-
Build a repeatable and defined process for regression testing.
This adds rigor and consistency to the regression test.
Summary
In dealing with all of the uncertainty, complexity and volume of regression test cases, one of the best things you can do to make regression testing manageable is to control the scope of it by carefully defining the essential cases. Automated test tools can be effective vehicles for reducing the manual testing burden, but there is still the need to design what needs to be tested. In fact, regression testing is the perfect use for automated test tools, as they can perform identical test actions multiple times and compare test results with exact precision.
However, regression testing in highly integrated and unstructured applications can be very difficult to perform and maintain, even with automated testing tools. Hopefully, using some of the concepts and techniques presented in this article, you can plan and perform regression testing in a way that is both effective and efficient.
